
The NLP Playbook: Essential Techniques for AI Development
Written by
Maryam Aslam
Last Updated: May 30, 2025

The Future of AI Starts Here
Opt for our AI development services to create intelligent, scalable and efficient solutions. Let’s push the boundaries together. Get Started with a Free Consultation Now.
AI development is making significant strides every day, and one of the most remarkable achievements is Natural Language Processing (NLP). In today's AI-driven era, NLP is evolving, aiming to bridge the gap between humans and machines. As technology has advanced, so has the need for systems that can interpret and communicate in natural human language. NLP enables machines to understand, analyze and generate human language to create smooth, intelligent interactions.
From real-time language translation to automated customer support, natural language processing techniques are becoming integral across industries. NLP powers chatbots, search engines, sentiment analysis tools, and more. Businesses are using NLP tools to transform how they communicate with customers and analyze large volumes of unstructured data.
In this article, we’ll explore the most effective NLP tools, key workflow stages, popular techniques, and how outsourced AI development services help integrate these NLP solutions into real-world applications.
Natural language processing techniques
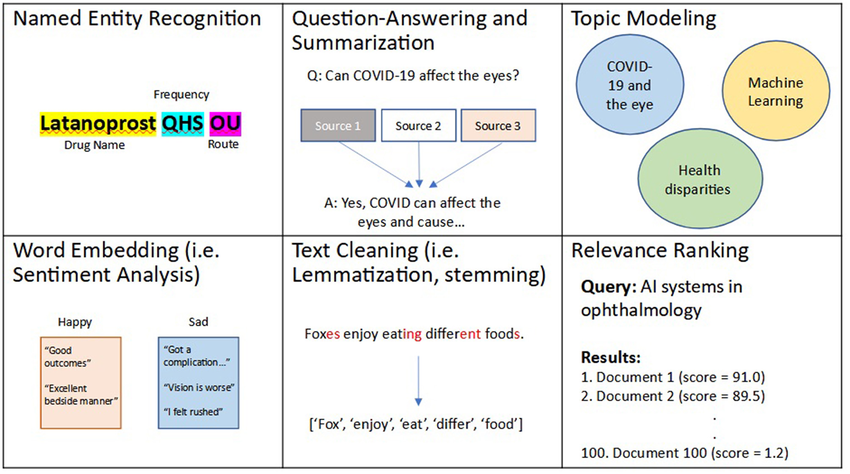
Source: ResearchGate
Tokenization and text preprocessing
Two of the most fundamental natural language processing techniques are tokenization and text preprocessing. These steps form the foundation for most NLP workflows.
Tokenization breaks down text, be it paragraphs, sentences or phrases, into smaller units known as tokens. These could be words, subwords or entire sentences. This segmentation helps machines process and understand language more effectively.
After tokenization comes text preprocessing, which involves refining the text to improve analysis:
Stopword removal → Eliminates common words like "and", "but", and "the" that do not carry significant meaning.
Stemming → Reduces words to their base forms (e.g., "running" becomes "run").
Lemmatization → Converts words to their dictionary form based on context (e.g., "better" becomes "good").
Preprocessing helps eliminate noise and focuses analysis on the most relevant parts of the text. Tools like spaCy and NLTK (Natural Language Toolkit) offer powerful modules for tokenization, stopword removal, stemming and lemmatization. These NLP tools improve accuracy and efficiency in downstream tasks like classification or summarization.
Part-of-speech tagging and syntactic analysis
Another core part of natural language processing techniques is identifying the part-of-speech (POS) of each word in a sentence such as noun, verb, adjective, etc. POS tagging clarifies the grammatical role of words, which is crucial for understanding sentence structure and meaning.
Following POS tagging is syntactic analysis, which uncovers the relationships between words by analyzing phrase structures and sentence composition. This is especially valuable for applications such as:
Sentiment analysis → Understanding whether a sentence conveys a positive or negative emotion.
Voice assistants → Parsing spoken commands accurately.
Search engines → Interpreting user intent precisely.
For example, the word "play" can function as both a noun ("a play at the theatre") and a verb ("play a game"). POS tagging ensures correct interpretation depending on context.
spaCy, Standard NLP, and other NLP tools offer advanced POS tagging and syntactic parsing, enabling developers to build AI with deeper linguistic understanding.
Named Entity Recognition (NER)
Named Entity Recognition (NER) is a powerful natural language processing technique used to identify key elements within a text such as people, organizations, dates, locations and more.
For instance, in the sentence "Tesla Inc. launched its new electric vehicle in November 2024", NER would label:
Tesla Inc. as an organization,
electric vehicle as a product or device,
November 2024 as a date.
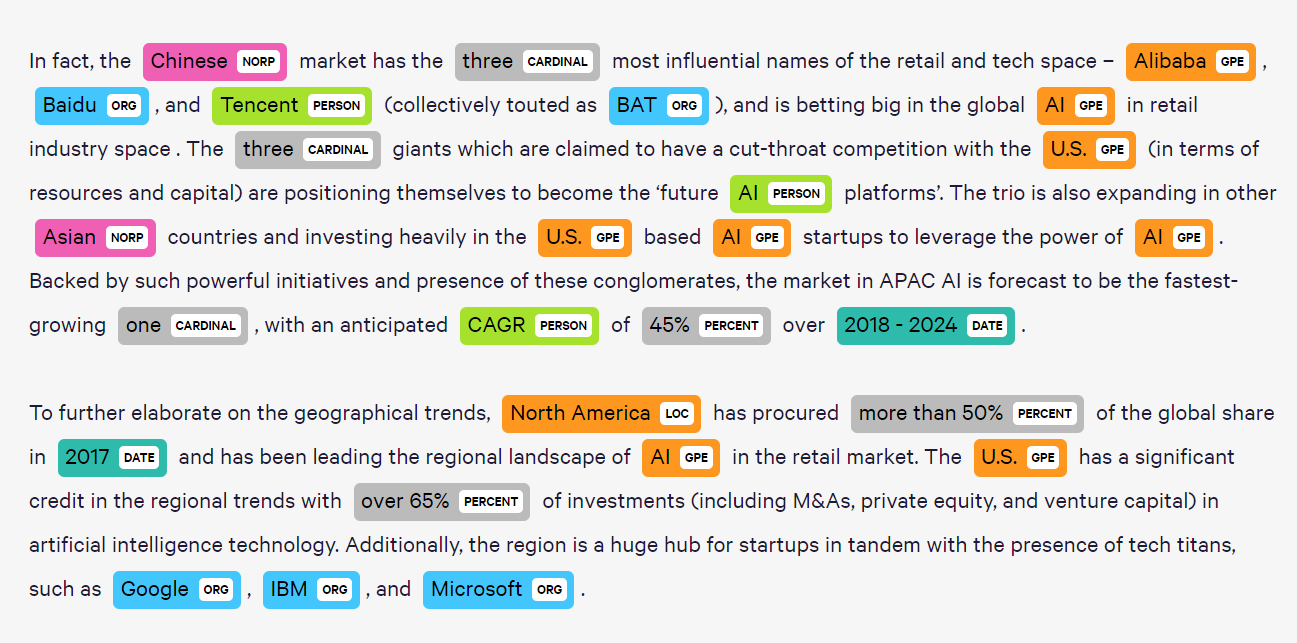
Source: NLP Course at Sapienza
This technique is particularly useful in:
Legal tech → Extracting case names, court dates and entities from legal documents.
Finance → Detecting company names and financial events in news articles or reports.
Publishing → Enhancing content tagging and improving searchability and recommendations.
By identifying critical data, NER supports more efficient content categorization, customer interaction and trend analysis, which makes it a key component of many NLP solutions.
Sentiment analysis and intent classification
Even with POS tagging and NER in place, machines need a way to determine how something is being said, this is where sentiment analysis and intent classification come in.
Sentiment analysis evaluates the emotional tone of a sentence or paragraph. It categorizes text as positive, negative, or neutral, which is especially useful for:
Customer feedback analysis,
Product reviews,
Social media monitoring.
Intent classification, meanwhile, determines the user’s goal behind the input such as asking a question, making a request or filing a complaint. This is critical for:
Chatbots,
Virtual assistants,
Automated ticketing systems.
Together, these techniques help build context-aware and personalized experiences. Tools like Dialogflow, Rasa and Hugging Face Transformers offer pre-built models and APIs for quickly integrating these capabilities into apps and services.
Text generation & summarization (Generative NLP)
Generative NLP is transforming the way content is created and condensed. It consists of two main techniques:
Text generation → Produces coherent, contextually relevant content based on a given input or prompt. Useful for drafting emails, chatbot responses and marketing copy.
Text summarization → Condenses long-form content into a digestible summary while retaining key information.
There are two types of summarization:
Extractive summarization → Selects and compiles key phrases or sentences directly from the original text.
Abstractive summarization → Rephrases content using different words to capture the essence in a more natural tone.
Popular NLP tools like GPT (Generative Pre-trained Transformer) and BERT (Bidirectional Encoder Representations from Transformers) provide the generative capabilities developers need to build smart automation tools.
As businesses grow, AI developers can use generative NLP to create scalable content solutions that require minimal human input but maintain high quality and personalization.
NLP pipeline for projects
Understanding these steps is critical to developing scalable and accurate NLP solutions. They guide how raw language data is transformed into meaningful insights or intelligent actions.
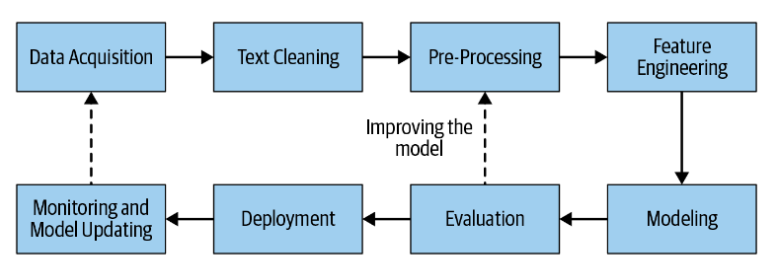
Source: Suchitra Jagadhane
1. Text collection
This is the starting point, where raw language data is gathered from relevant sources. Depending on the use case, sources may include:
Webpages (blogs, product descriptions, news sites),
Customer reviews, chat logs or call transcripts,
Social media posts, forums or public APIs like Twitter,
Internal documentation such as CRM data or support tickets.
The quality and diversity of data collected directly impact the performance and bias-resistance of the final model.
2. Preprocessing
Before feeding the data into a model, it must be cleaned and standardized. Preprocessing involves multiple steps:
Lowercasing → Ensures uniformity by converting all text to lowercase.
Removing punctuation and special characters → Reduces noise in the dataset.
Stopword removal → Eliminates common filler words that carry little analytical value.
Spelling correction and normalization → Accounts for typos, slang, or informal language.
Stemming and lemmatization → Reduces words to their root or dictionary form to improve pattern recognition.
This stage ensures the input data is clean, consistent, and easier to process for downstream tasks.
3. Tokenization
Tokenization splits text into individual units that can be analyzed, these could be:
Words (word-level tokenization),
Subwords or characters (useful for handling out-of-vocabulary words),
Sentences (sentence-level tokenization).
Proper tokenization helps maintain the context and structure of the language, enabling more accurate linguistic analysis. For languages with complex grammar (like Chinese or Arabic), advanced tokenizers are required.
4. Feature extraction
At this stage, textual tokens are converted into numerical formats so machine learning models can process them. Common feature extraction methods include:
Bag-of-Words (BoW) → Counts word occurrences but lacks context.
TF-IDF (Term Frequency-Inverse Document Frequency) → Weighs words based on frequency and uniqueness across documents.
Word embeddings → Dense vector representations (e.g., Word2Vec, GloVe or contextual embeddings like BERT) that capture semantic meaning and word relationships.
Feature extraction bridges the gap between unstructured language and structured data models.
5. Modeling
This is where machine learning (ML) or deep learning (DL) algorithms are applied to learn from the extracted features. Depending on the goal, you may use:
Classification models for spam detection or sentiment analysis,
Sequence models (like RNNs or Transformers) for tasks such as translation or summarization,
Clustering or topic modeling for document classification or recommendation systems.
Model selection depends on task complexity, data size and real-time requirements.
6. Evaluation
Once the model is trained, it needs to be validated for accuracy and reliability. Common evaluation metrics include:
Accuracy → Percentage of correct predictions.
Precision and recall → Balance between false positives and false negatives.
F1-score → Harmonic means of precision and recall.
Confusion matrix → Visual summary of prediction results.
Evaluating models with the right metrics ensures they meet performance expectations, especially in high-stakes use cases like legal or financial NLP applications.
7. Deployment
Finally, the trained model is integrated into a real-world application or service, such as:
Conversational chatbots,
Voice assistants,
Recommendation engines,
Email classifiers or content moderators.
Deployment also involves setting up APIs, model monitoring, and retraining pipelines to keep the system adaptive and up-to-date.
Together, these seven stages form a comprehensive framework that AI development teams follow to build, refine, and scale NLP solutions that drive real business outcomes.
NLP tools & platforms for development
Developers rely on a suite of NLP tools to implement solutions tailored to different tasks:
spaCy → Known for high-speed processing in POS tagging, tokenization, and NER.
NLTK (Natural Language Toolkit) → A comprehensive Python library for linguistics and educational use.
Hugging Face Transformers → Offers pre-trained models like GPT and BERT for tasks like classification and summarization.
OpenAI (ChatGPT, Codex) → Excellent for generative tasks, including text completion and dialogue design.
These platforms form the backbone of AI development, empowering businesses to build smart, responsive applications.
What makes NLP work in 2025?
As we go through 2025, natural language processing techniques are becoming more advanced, allowing increasingly intuitive AI-human interactions. From personalized chatbots to intelligent customer support systems, NLP is a central part of modern AI.
But NLP isn’t just about using popular tools, it’s also about implementing tailored NLP solutions that align with business needs. Off-the-shelf models often fall short when personalization and precision are key. That’s why businesses turn to expert AI development services.
Pixelette Technologies is one such provider that provides businesses craft custom NLP stacks. From data collection to model deployment, we help organizations in the United Kingdom, Europe and USA move from raw language data to actionable, real-time solutions.

